The Instability-Abstractness-Relationship — An Alternative View
One of the most favorite topics of mine is improving software quality — and software maintainability in particular — through the means of decomposition. A problem associated with that, of course, is how to measure the success of a particular strategy chosen. Software metrics are a common means used to project the current state of a system into something seemingly measurable. In today’s blog post, I would like to take a closer look at the Instability-Abstractness-Relationship and whether it can help us to objectively measure the quality of a particular system design.
The Instability-Abstractness-Relationship is a software metric to measure the design quality of Java packages, originally introduced in “Agile Software Development — Principles, Patterns, and Practices” by Robert C. Martin. If you search the internet for the topic you find a gazillion of blog posts all summarizing the idea (we will, too, in a second). But hardly any of them critically discuss the ideas, goals, and assumptions made by the author to get to a clear picture of what we are actually dealing with. It is a software quality metric, the author is (in)famous, so it has got to be good, right? Let’s see.
The metric
In short, the instability of a package — or any other encapsulation unit of the system — is supposed to be inversely proportional to its abstractness. For those who have not heard about these terms yet, here is a short description of what they describe. Instability describes the ratio of efferent (outgoing) dependencies of a package in relation to the afferent (incoming) ones. A package without any outgoing dependencies is considered stable. On the contrary, the more incoming dependencies are targeting a package, the less stable it is considered. Abstractness, on the other hand, is supposed to express how “abstract” — and we are about to get to what that means in a second — a package is. The fundamental idea of combining these two metrics is that the more stable a package is, the more abstract it is supposed to be.
Martin defines formulas for how to calculate values for each of the metrics and combines them into a quality metric in terms of the distance from an assumed ideal. It is described as the main line that parts the different zones of the chart. Numeric values for each of the metrics can be calculated for every package in the application, and the resulting distance from the main line is considered an indicator of a package’s design quality.
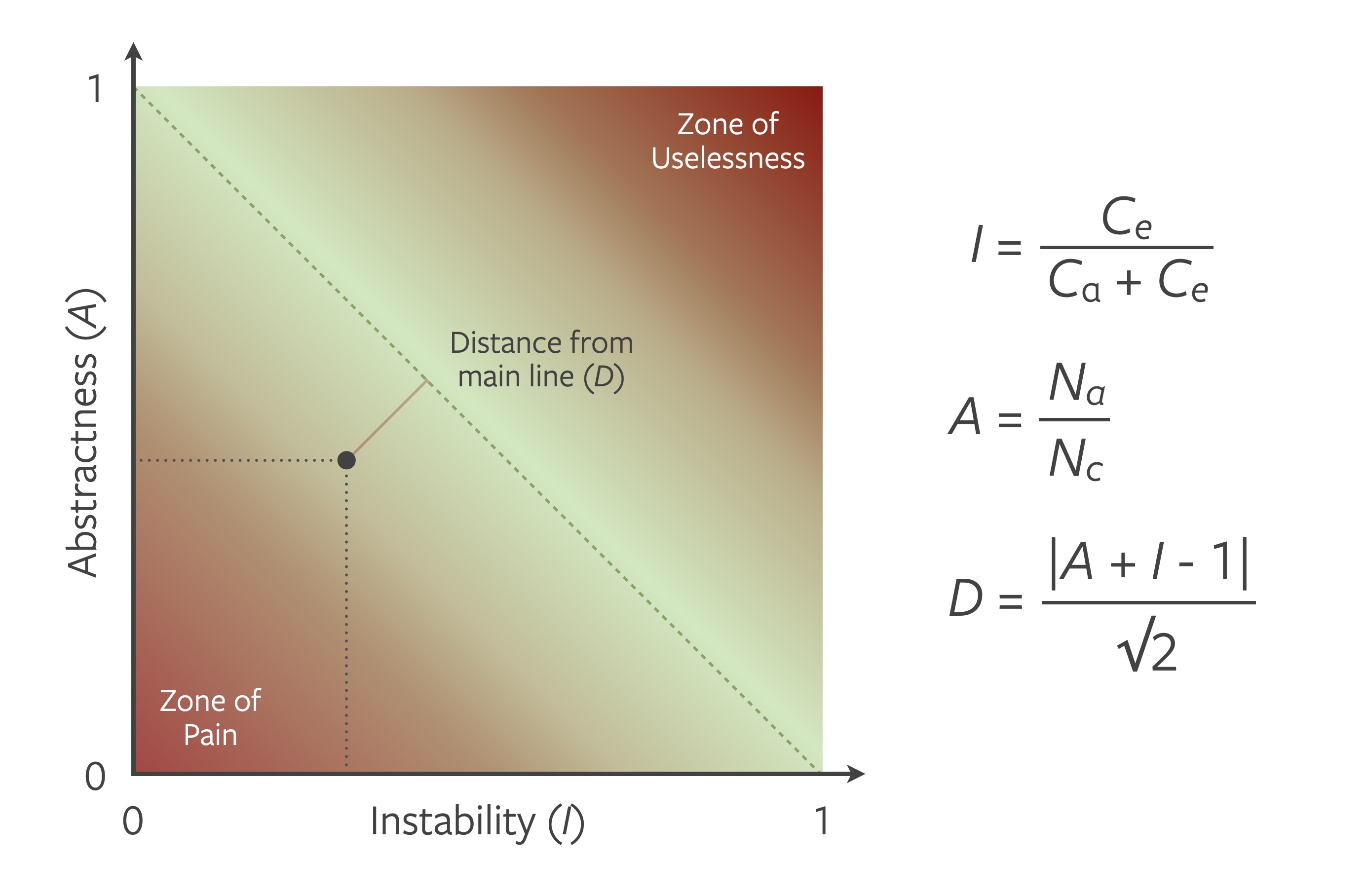
In fact, the combined metric is assigned a negative quality value by assigning areas in the diagram which a package is not supposed to live. One of these areas is defined as the “Zone of Pain” which entails stable packages that are not abstract. The other is the “Zone of Uselessness”, that combines an unstable package (virtually no incoming dependencies) with a lot of abstraction.
This metric and its alleged proposition about a package’s design have been around for more than two decades. Software architecture quality tools have provided these metrics, and millions of developers have looked at these numbers to “optimize” their code base or at least evaluate its quality.
What are we even doing here?
If you zoom out of all the mathematics a bit, problems with the approach become pretty obvious immediately. Let us start by benevolently assuming the metric measures what it is supposed to measure. As a developer of an individual package, the primary means of influencing the overall metric is increasing or decreasing the abstractness part of the equation. Let us say we find ourselves in the “Zone of Pain”, meaning we face many afferent dependencies but are primarily exposing concrete types.
While we surely cannot cut any of the incoming dependencies (the depending packages will need access to our functionality), we can certainly introduce a few more interfaces, can we not? Start your most favorite IDE’s refactoring tools, for each class depended on, extract an interface, and let the client code be adapted to refer to those interfaces where possible. Job done, code base improved, correct? Unfortunately, not a bit.
Abstractness VS. Abstraction
The mistake that Martin makes is equating abstractness with abstraction and that problem is hidden in plain sight. The relevant section is titled “Measuring Abstraction” and it immediately starts with “The A metric is a measurement of the abstractness of a package.” (page 265) So, what is the difference? Just because we extract an interface from a class — and by that, raise the abstractness of the package — the interface is not semantically more abstract than the implementation was before. And it is just as susceptible to consequences of changes to it.
Let us move on to the anticipated effect of the allegedly higher abstraction. Martin writes: “Consider a package in the area of (0, 0). … Such a package is not desirable because it is rigid. It cannot be extended because it is not abstract.” The goal he sets out for stable code is extensibility. But why? What kind of extension to a codebase becomes easier if you deal with an abstract type versus a concrete one? Correct! It is easier to provide a new implementation for a particular, logical interface if it is technically an interface, too. Now, here is the crucial question: are the changes that we need to make to a code base in arbitrary business applications really primarily adding new implementations of already existing interfaces?
Change patterns
What might work in a theoretical example of, let us say, the collection library.
It is of course easier to add a new implementation of List if client code depends on that interface and not an already existing implementation like ArrayList.
We still might have to deal with cases in which that code still has to refer to the concrete type to create instances of it.
Modern Java versions allow to define static factory methods on interfaces to mitigate that problem.
That said, at least in my experience change patterns in business applications usually either require the introduction of completely new abstractions or the modification of existing types to introduce new methods etc.
For those kinds of changes, it is mostly irrelevant if you need to introduce them on an interface or an implementation.
Some might even consider the extra interface primarily causing additional work.
So while an interface on a different level of abstraction might indeed allow to shield client code from implementation details it does not have to know about, simply calculating abstract versus concrete types of a particular programming language is misleading at best and harmful at worst. Developers feel incentivized to either remove or add interfaces for no other reason than meeting metric numbers without positively affecting a code base’s design. To the contrary, introducing new interfaces for the sake of meeting some metric results in more code that we will have to adapt to implement new features.
Summary
The Abstractness-Instability-Relationship defines a code quality metric that does not support change patterns of modern applications. By both missing the actual quality goal and misinterpreting abstractness as level of abstraction, it does not form a good metric to judge the quality of a package design.
Oliver Drotbohm
Soul Power!
chaos.social/@odrotbohm
github.com/odrotbohm
linkedin.com/in/odrotbohm
bsky.app/profile/odrotbohm.de
info@odrotbohm.de
